Table of Contents
Machine Learning Pipeline: Deep Learning Process Tutorial
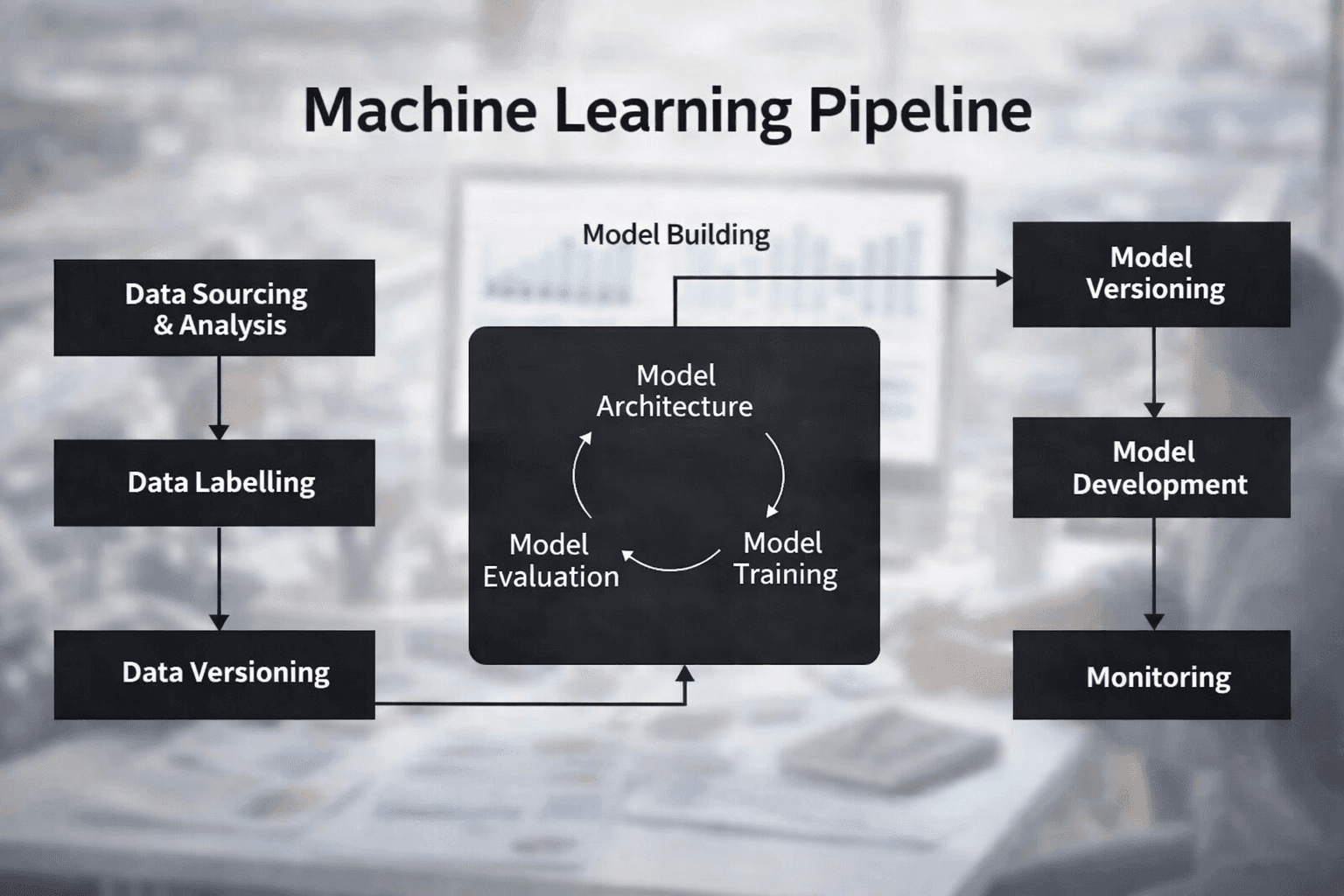
A Machine Learning Pipeline is a well-arranged set of steps used to build, train, and deploy machine learning models effectively. In data science, pipelines act as a chain of processes that transform raw data into reliable predictive outputs. By clearly defining each phase of model development, a pipeline reduces errors, improves consistency, and makes it easier to scale solutions for real-world applications.
What Is a Machine Learning Pipeline For?
At its core, a machine learning pipeline is a sequence of steps in which data processing and model development phases are connected. The output of one step becomes the input to the next, allowing data to flow seamlessly from collection to prediction.
Main Goals of a Machine Learning Pipeline
Automation
Routine tasks such as data preparation and model training can be standardized and automated, reducing manual effort and errors.
Reproducibility
Re-running the same pipeline on the same data produces consistent results, making experiments repeatable and reliable.
Efficiency
Organized workflows save time and optimize computational resources, which is critical for handling large datasets and complex models.
Data Collection
Data collection lays the foundation for the rest of the pipeline. Data can be gathered from databases, APIs, devices, logs, or user interactions. The quality and relevance of this data strongly influence how well the final model will perform.
Data Preprocessing
Raw data is often noisy, incomplete, or inconsistent. Data preprocessing cleans and prepares it for use in the pipeline.
Data Cleaning
This includes handling missing values, removing duplicates, and normalizing outliers to improve data reliability and trustworthiness.
Data Transformation
Techniques such as normalization, scaling, and encoding are applied so that data is in the right format for downstream algorithms and models.
Feature Engineering
Feature engineering focuses on creating or selecting features that help maximize a model's predictive accuracy. It relies on domain expertise and insights from exploratory analysis.
Feature Selection
Irrelevant or redundant features are removed to simplify the model, reduce overfitting, and speed up training.
Feature Extraction
New features are derived from existing ones to capture important patterns and structures that are not directly visible in the raw data.
Model Selection and Training
Model selection involves choosing algorithms that best match the problem. Options can include regression models, decision trees, support vector machines, ensemble methods, or deep learning models.
During model training, the chosen algorithm learns patterns from the processed data. Its parameters are adjusted to minimize the error between predicted and actual values while maximizing accuracy.
Hyperparameter Tuning
Hyperparameters are systematically adjusted to improve performance on unseen data, often using methods such as grid search, random search, or Bayesian optimization.
Model Evaluation and Deployment
After training, it is essential to evaluate the model using new, unseen data. Metrics such as accuracy, precision, recall, F1 score, or mean squared error are chosen based on the problem type.
Validation Techniques
Techniques like cross-validation provide a fair estimate of how the model will perform on future data by testing it on multiple splits of the dataset.
Model Deployment
Deployment integrates the trained model into a production environment, where it can generate predictions in real-time or on batches of data. This marks the transition from experimentation to practical use.
Monitoring and Maintenance
Once deployed, models must be continuously monitored. As data distributions shift over time, model accuracy can degrade, a phenomenon known as data drift or concept drift.
To maintain performance, models may need to be retrained on fresh data or the pipeline may require updates to better reflect current conditions.
Significance of Machine Learning Pipelines in Real-Life Scenarios
The key advantage of a machine learning pipeline is that it brings clarity and discipline to the modeling process. By defining distinct phases, teams can communicate more effectively, track issues, and resolve problems quickly.
Pipelines also support scalability, making it easier to adapt models to larger datasets and evolving business requirements without redesigning the workflow from scratch.
Conclusion
From data processing and feature engineering to model development and deployment, the machine learning pipeline breaks complex work into a simple, continuous process. It turns complicated problems into manageable steps while improving efficiency and accuracy.
Structured machine learning pipelines will continue to be a crucial component of real-world AI systems, supporting robust, scalable, and maintainable solutions.
Frequently Asked Questions
Common Questions About Machine Learning Pipelines